Comparing Performance
After specifying the foreign key - primary key constraints, and creating and refreshing analytical views recommended by Smart Acceleration, re-load the dashboard.
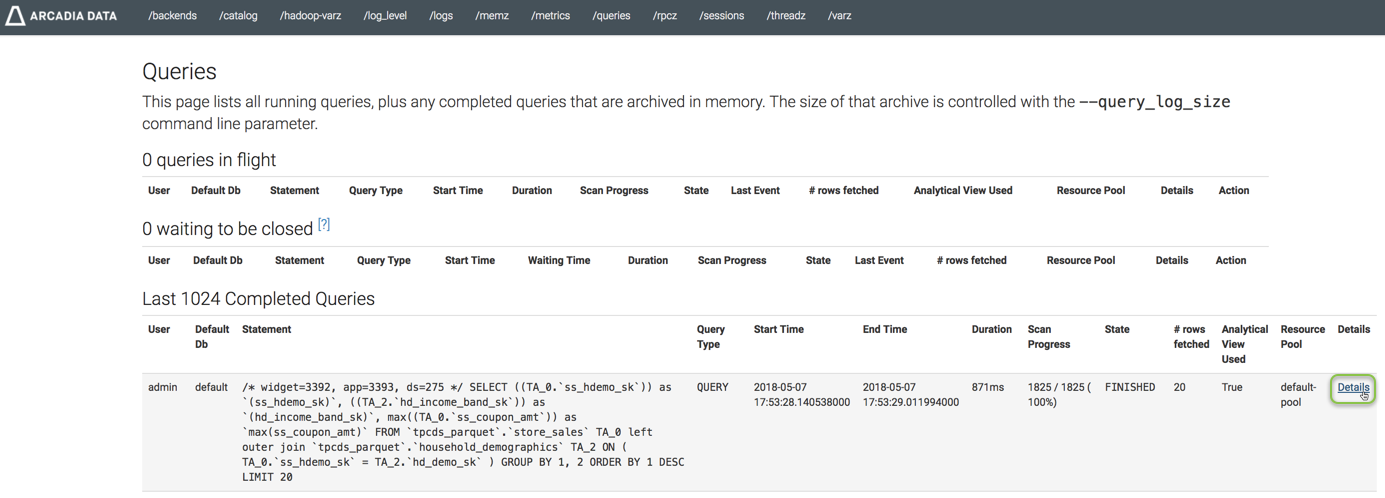
Navigate to the Admin interface (port 3500) to view the queries, their run time, and other details.
Click the Queries tab to see most recent results, select the query that corresponds to the visual that demonstrates eager aggregation, and click Details.
Here, we examine widget #3392.
Query Re-write
/* widget=3392, app=3393, ds=275 */
SELECT ((TA_0.`ss_hdemo_sk`)) as `(ss_hdemo_sk)`, ((TA_2.`hd_income_band_sk`)) as `(hd_income_band_sk)`, max((TA_0.`ss_coupon_amt`)) as `max(ss_coupon_amt)`
FROM `tpcds_parquet`.`store_sales` TA_0 left outer join `tpcds_parquet`.`household_demographics` TA_2 ON ( TA_0.`ss_hdemo_sk` = TA_2.`hd_demo_sk` )
GROUP BY 1, 2
ORDER BY 1 DESC
LIMIT 20Compare it to the re-written query, which includes replacement using analytical views, and re-ordering with eager aggregation:
SELECT av_1_ds_275.ss_hdemo_sk `(ss_hdemo_sk)`, (TA_2.hd_income_band_sk) `(hd_income_band_sk)`, max_decimal_finalize(av_1_ds_275.`_c0`) `max(ss_coupon_amt)`
FROM tpcds_parquet.av_1_ds_275 av_1_ds_275 LEFT OUTER JOIN tpcds_parquet.household_demographics ta_2 ON (av_1_ds_275.ss_hdemo_sk = TA_2.hd_demo_sk)
GROUP BY 1, 2
ORDER BY 1 DESC
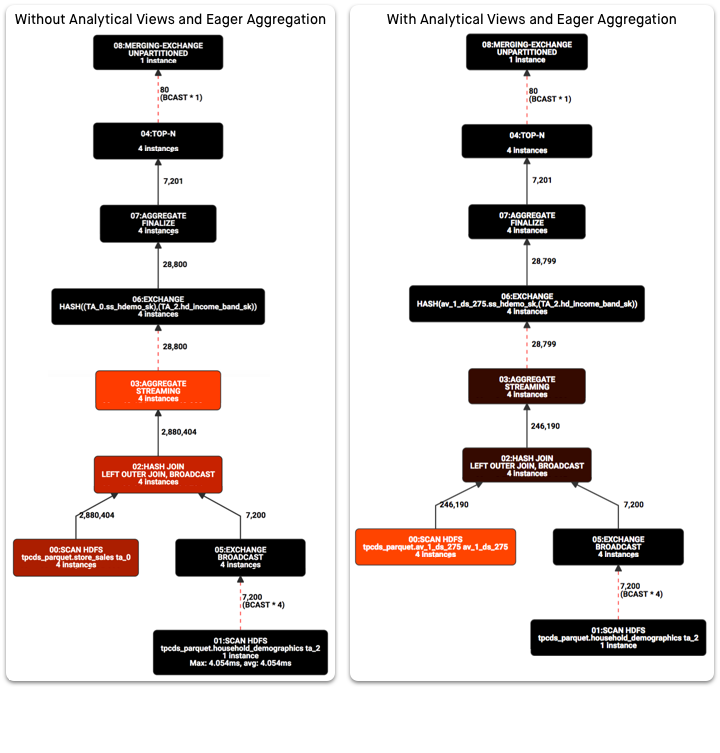
LIMIT 20Changes to the Execution Plan
Note the changes to the how query runs, with particular attention to the highlighted
sections and over a 1,000 times improvement in the number of rows emerging from the
SCAN HDFS step.