Data API
Arcadia Enterprise provides an interface for applications that fetch data using a REST interface.
Typically, users access Arcadia’s web server through a web browser, and the interface is entirely visual. This visual interface interacts directly with Arcadia’s data layer, which in turn provides seamless access to modeled data, integrated security controls, fast access to data in connected systems, and access to advanced analytics.
Sometimes, operational data applications do not need access to Arcadia’s visual layer, but require direct access to the data layer. For these purposes, Arcadia supports a Data API that provides operational data applications with direct access to data.
See the following sections for more information about the Data API interface.
Enabling Data API
Before invoking the Data API, you must first enable Data API in the configuration file of the Arcadia Web Server and obtain an API key.
This article includes the following topics:
Enabling Data API
- Add the following settings in the configuration file of the Arcadia Web Server:
ENABLE_API_KEYS = TrueDATA_API_ENABLED = True
- Restart ArcViz service.
Depending on your installation, configure these settings as follows:
- Cloudera Manager
On the Cloudera Manager interface, enter the settings in the Arcadia Visualization Server Advanced Configuration Snippet (Safety Valve) for settings_cm.py field.
- Ambari
On the Ambari interface, enter the settings in the ArcViz Settings field.
- MapR
For MapR, enter the settings directly in the
settings.pyfile.
Obtaining an API Key
In situations where users do not login directly into Arcadia’s visual layer, you must obtain an API key. See Creating New API Keys.
After obtaining an API Key, you can use it to authenticate the user to access the dataset, and invoke Arcadia’s data layer at the following endpoint:
http://<server>:<port>/arc/api/data
Proceed with using the Data API interface. See Example of Data API Usage.
Example of Data API Usage
To use a Data API interface, you need to enable the Data API, obtain an API key, and then invoke the Data API.
Note that the API provides no discovery interfaces to understand the structure and format of the data. The invoker of the interface must be familiar with the dataset they are using, and what dimensions, aggregates, and filters are appropriate for each use case. To construct the request payload, see Data API Request Payload.
Here is an example of a Data API python code that interfaces with the Cereals dataset that ships as a sample within most Arcadia Enterprise installations. Note that the dataset ID used in this example is 11, but it may be different on your system.
In this example, we are supplying the API Key that authorizes the user to access the dataset.
import requests
import json
# CHANGE the following endpoint to your site-specific endpoint:
url = 'http://127.0.0.1:38888/arc/api/data'
def _fetch_data(dsreq):
headers = {
# CHANGE the following key to your site specific API key
'Authorization': 'apikey krGyk1sYpSAkuaxzc0oUbcFdUu9McOwujKVCc2BjaFsgr1J7'
}
params = {
'version': 1,
'dsreq': dsreq,
}
r = requests.post(url, headers=headers, data=params)
if r.status_code != 200:
print 'Error', r.status_code, r.content
return
raw = r.content
d = json.loads(raw)
print '\nData Request being sent is:\n', \
json.dumps(json.loads(dsreq), indent=2)
print '\nData Response returned is:\n', json.dumps(d, indent=2)
def main():
# CHANGE the following dsreq to a data request of your choice. On an existing dashboard, you can
# view the details of the data-request by opening the Performance Profile interface
# using the keyboard shortcut Shift + Control + G.
dsreq =
"""{"version":1,"type":"SQL","limit":100,
"dimensions":[{"type":"SIMPLE","expr":"[manufacturer] as 'manufacturer'"}],
"aggregates":[{"expr":"sum([sodium_mg]) as 'sum(sodium_mg)'"},
{"expr":"avg([fat_grams]) as 'avg(fat_grams)'"},
{"expr":"sum(1) as 'Record Count'"}],
"filters":["[cold_or_hot] in ('C')"],
"dataset_id":11}"""
_fetch_data(dsreq)
if __name__ == '__main__':
main()After a successful data request payload, the system returns an HTTP response of type
text/json. For an example of a response payload, see Example of a Response Payload.
Data API Request Payload
Before invoking the Data API, you must familiarize yourself with the syntax of the request payload.
This topic includes the following sections:
Syntax of a Request Payload
{
"version":version_number,
"type":"SQL",
"limit":number_of_rows,
"dimensions":
[{
"type":"SIMPLE/SEGMENT",
"expr":"[dimension_1] as 'dimension_value_1',
"expr":"[dimension_2] as 'dimension_value_2',
"expr":"[dimension_n] as 'dimension_value_n',
"order": {"asc": True/False, "pri": order_sequence}
}],
"aggregates":
[{
"expr":["aggregate_1] as 'aggregate_value_1',
"expr":["aggregate_2] as 'aggregate_value_2',
"expr":["aggregate_n] as 'aggregate_value_n',
}],
"filters":
[
"[filter_1] in ('filter_value_1')",
"[filter_2] in ('filter_value_2')",
"[filter_n] in ('filter_value_n')"
],
"having":
[
"[aggregate_1]) > aggregate_value_1"
],
"dataset_id":dataset_id_number
} Parameters of a Request Payload
The request payload parameters are defined as follows:
- version
Specifies the version of the API. This is used for backward compatibility in case the API changes in the future. This is a mandatory parameter. For example, version 1.
-
type
Specifies the type of query. This is a mandatory parameter. For example, SQL.
- limit
Specifies the number of rows to return. This is a mandatory parameter.
- dimensions
List of zero or more dimensions. Specifying no dimensions or aggregates returns all columns from the dataset. Each item in the list specifies a dimension that is requested, and has the following structure of key value pairs:
type- Either
SIMPLEorSEGMENT. Default isSIMPLE. Use field descriptions forexprandorderwithSIMPLEtype. expr- Either a dimension or an aggregate with the following format: "expr":"[dimension_1] as 'dimension_value'.This is a mandatory parameter.
order- Maximum of two key value pairs: ‘asc’, which is set to True or False. This indicates the order and priority, which is set to an integer and specifies the sequence in which the order is to be applied.
- aggregates
List of zero or more dimensions. Specifying no dimensions or aggregates will return all columns from the dataset. Each item in the list specifies an aggregate that is requested, and has the following structure of key value pairs:
- expr
- Specifies one aggregate with the following format: [{"expr":["aggregate_1] as 'aggregate_value_1'}].
- dataset_id
Specifies the ID of the dataset object to run the data query. This is a mandatory parameter.
- filters
Specifies a comma-separated list of filter expressions that apply to the dataset using the ‘WHERE’ clause. All the filters specified are combined with an ‘AND’ operation. These filters are applied as the ‘WHERE clause in the generated SQL. This is an optional parameter.
- having
Specifies expressions to filter the dataset using the
HAVINGclause. Therefore, this parameter has an aggregation comparison in them. This is an optional parameter.
Example of a Request Payload
Here is an example of a Data API request payload that interfaces with the Cereals dataset that ships as a sample within most Arcadia Enterprise installations.
{
"version":1,
"type":"SQL",
"limit":100,
"dimensions":
[{
"type":"SIMPLE",
"expr":"[manufacturer] as 'manufacturer'",
"order": {"asc":False, "pri":1
}],
"aggregates":
[{
"expr":["avg([fat_grams]) as 'avg(fat_grams)'",
"expr":["sum(1) as 'Record Count'"
}],
"filters":
[
["[cold_or_hot] in ('C')"]
],
"having":
[
["[avg([fat_grams]) < 5"]
],
"dataset_id":11 Data API Response Payload
After a successful data request payload, the system returns an HTTP response of
type text/json.
Syntax of a Response Payload
{
"info": [
"Query:SELECT query
],
"coltypes": [
"type_of_single_column",
"BIGINT"
],
"colnames":[
"column_name_1",
"column_name_2",
"column_name_n"
],
"rows": [
[
"row_information_1",
"row_information_2",
"row_information_n"
]
]
}Parameters of a Response Payload
The response payload parameters are defined as follows:
- info
String of the raw SQL query that is executed.
- coltypes
Array of strings, where each string specifies the type of a single column returned by the data request.
- colnames
Array of strings, where each string specifies the name of a single column returned by the data request. This contains the alias for the columns as specified in the initial request.
- rows
Array of arrays, where each inner array represents a single row of information returned by the data request.
Example of a Response Payload
Here is an example of a Data API response payload:
{
"info": [
"Query:SELECT TA_0.`manufacturer` as `manufacturer`, sum(1) as `Record Count`\n
FROM `main`.`cereals` TA_0\n WHERE TA_0.`cold_or_hot` in ('C')\n GROUP BY 1\n LIMIT 100"
],
"coltypes": [
"STRING",
"BIGINT"
],
"colnames": [
"manufacturer",
"Record Count"
],
"rows": [
[
"General Mills",
22
],
[
"Kelloggs",
23
]
]
}Accessing Data API Request Payload
To avoid creating Data API requests from scratch, Arcadia Enterprise provides access to details of the data-requests.
This task is optional.
To access details of Arcadia visual Data API requests, follow these steps:
- Add the following settings in the configuration file of the Arcadia Web Server:
ENABLE_DSREQ_PERF_DISPLAY = TrueCOMPRESS_DSREQ = True
- Restart ArcViz service.
- Open an existing dashboard. We selected Cereals.
- Use the keyboard shortcut Shift + Control + G to open the Performance Profile interface.
- Hover over a line that represents a visual ID (we selected
377), and view the duration, type, and details of the query performed on that visual. This query uses the same API and includes the details of the data requests. You can use this dataset request as the payload for your Data API call.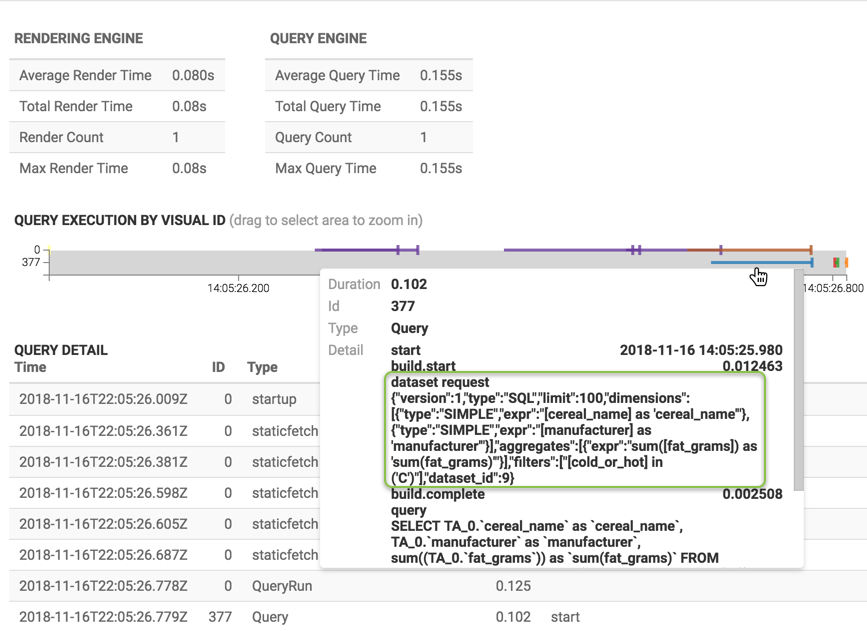
For more information on accessing the Performance Profile interface, see Monitoring Dashboard Performance Profile.